目次
モチベーション
実装する頻度自体は高くないものの、クラスタの可用性を高めることや管理ノードの負荷分散を目的としてSlurmの管理ノードを冗長構成にしたい瞬間があります。そして私も管理ノードを冗長化していたことで救われた経験が過去に何度かありました。
しかし、都度設定方法を調べて構成している気がするので、この際ブログに記事として残して見返せるようにしようというのが執筆の背景です。
クラスタ構成 / 検証すべき動作
手元に潤沢な計算資源が無いため、AWS上にEC2を配備しクラスタを構成しました。クラスタの構成は下図の通り。検証用途でセキュリティに注意を払う必要が無いため、Public Subnet上にマシンを展開しました。予算の都合上、すべての計算ノードは t3.micro + ubuntu 24.04 LTS の組み合わせで構成しています。Slurmのバージョンは24.05を使用しています。
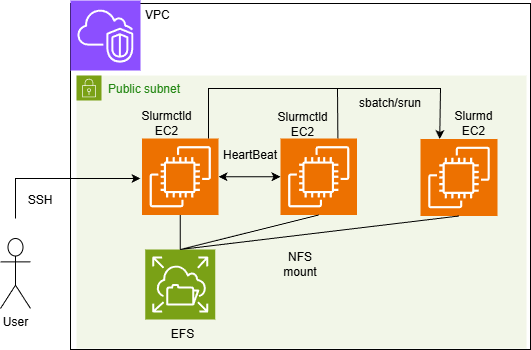
上図において、「Slurmctld」と記載のあるEC2が管理ノードとなります。これらのノード間でHeartbeatを監視し、主系として動作する一方のSlurmctldがDownした際に、待機系として動作する他方のSlurmctldに処理を引き継ぐことを確認します。また、引継ぎ処理の間に計算ノードである「Slurmd」上で実行されているジョブが継続していることも確認する必要があります。
更に復旧後の動作としても、主系の管理ノードが再度Upしてきた際に、待機系の管理ノードが主系の管理ノードに処理を再度引き渡していることもチェックする必要があります。
主系 / 待機系 管理ノードのSlurm設定
今回の検証ではParallelCluster等は使わないないため、1から管理ノードを立ち上げます。その際、私はこちら(参考[1])の記事を参考にさせていただきました。mailutilsの設定は行わずにslurmctldのインストールに成功しました。一応、実行したコマンド群を以下に貼ります。
### パッケージ群のインストール処理
sudo apt update
sudo apt install -y build-essential
sudo apt install -y munge libmunge-dev
### 参考とした記事から加筆 FESのNFSマウントが必要なため
sudo apt install -y nfs-common
### munge関連の認証設定からサービス起動まで
sudo dd if=/dev/random of=/etc/munge/munge.key bs=1024 count=1
sudo chown munge:munge /etc/munge/munge.key
### 後々、munge.keyを各サーバへ共有する必要がある。
sudo chmod 400 /etc/munge/munge.key
sudo systemctl restart munge
### Slurmをwgetでダウンロードして展開まで。SlurmのVersionは適宜変更ください
cd ~
wget https://download.schedmd.com/slurm/slurm-24.05.3.tar.bz2
tar -jxvf slurm-24.05.3.tar.bz2
cd ~/slurm-24.05.3
### ビルドしてインストールまで
./configure
make
sudo make install次にslurm.confを各自の環境に合わせて作成します。こちら(参考[2])で簡易設定を作成しました。slurm.confの設定内容を以下に貼ります。ここで冗長化時に配慮すべき点が3点あります。
# slurm.conf file generated by configurator easy.html.
# Put this file on all nodes of your cluster.
# See the slurm.conf man page for more information.
#
ClusterName=Redundant-cluster
### Point.1 最初にSlurmctldHostに指定した管理ノードが主系、以降が待機系になる
### 今回主系のホスト名をSlurm-Master, 待機系のホスト名をSlurm-Secondaryとした
SlurmctldHost=Slurm-Master
SlurmctldHost=Slurm-Secondary
#
#MailProg=/bin/mail
#MpiDefault=
#MpiParams=ports=#-#
ProctrackType=proctrack/cgroup
ReturnToService=1
SlurmctldPidFile=/var/run/slurmctld.pid
#SlurmctldPort=6817
SlurmdPidFile=/var/run/slurmd.pid
#SlurmdPort=6818
SlurmdSpoolDir=/var/spool/slurmd
SlurmUser=slurm
#SlurmdUser=root
### Point.2 StateSaveLocationに指定するディレクトリを共有ディレクトリに設定する
### これによって各管理ノードから、クラスタの管理状況を参照できるようにする
StateSaveLocation=/efs/var/spool/slurmctld
#SwitchType=
TaskPlugin=task/affinity,task/cgroup
#
#
# TIMERS
#KillWait=30
#MinJobAge=300
#SlurmctldTimeout=120
#SlurmdTimeout=300
#
#
# SCHEDULING
SchedulerType=sched/backfill
SelectType=select/cons_tres
#
#
# LOGGING AND ACCOUNTING
#AccountingStorageType=
#JobAcctGatherFrequency=30
#JobAcctGatherType=
#SlurmctldDebug=info
SlurmctldLogFile=/var/log/slurmctld.log
#SlurmdDebug=info
SlurmdLogFile=/var/log/slurmd.log
#
#
# COMPUTE NODES (分かりやすいように計算ノードのホスト名をcompute01とした)
NodeName=compute01 CPUs=2 State=UNKNOWN
PartitionName=Partition01 Nodes=ALL Default=YES MaxTime=INFINITE State=UP配慮すべき3点について、Point1, 2に基づいた加筆項目2点 + 注意事項1点を下記に記載します。
- 複数の管理ノードをSlurmctldHostとして記述すること (主系 → 待機系の順番)
- StateSaveLocationを共有ディレクトリに設定し、クラスタの稼働状況を共有すること
- slurmd, slurmctld関連のログやpidファイルはローカル領域保存のままにすること
最後の項目は、他の管理ノードや計算ノードとログの書き込みが競合してしまうことを防ぎたい意図があり記載しました。私も混乱しがちなため・・・。その他に些細な点として、各マシンの名前解決ができるようにhostsに登録するなり、DNSに登録するなりの作業をお願いします。
上記の設定を加味しながら、再び参考[1]の項番6以降を設定してください。念のため、以下にもコマンドリストを記述します。途中、共有ディレクトリ上へのslurm設定を追記しています。
### slurmctldをサービスとして登録し、自動起動するように設定する(未だ起動しない)
cd ~/slurm-24.05.3
sudo cp /etc/slurmctld.service /etc/systemd/system
sudo systemctl enable slurmctld.service
### slurmユーザを登録する。全ノードでslurmユーザのUID/GIDは揃えること
sudo adduser slurm
sudo gpasswd -a slurm sudo
sudo usermod -aG syslog slurm
### 一部EFS上にディレクトリを構成するよう変更する。
### EFS上に生成するものは、主系で一度作成した後は待機系で再度作成する必要はない。
sudo mkdir -p /efs/var/spool/slurmctld
sudo chown -R slurm:slurm /efs/var/spool/slurmctld
sudo chmod -R 750 /efs/var/spool/slurmctld
sudo chown slurm:slurm /usr/local/etc/slurm.conf
sudo chmod 644 /usr/local/etc/slurm.conf
### サービス起動とrunning状態になっていることの確認
sudo systemctl start slurmctld
sudo systemctl status slurmctld以上で設定完了です。待機系管理ノードについても基本的な設定は同じですが、munge.keyについては再生成することなく主系で作成したものをパーミッションを保持したままコピーしてお使いください。新規に作ると認証エラーが表示され、mungeサービスが起動しません。
同様にslurm.confも各ノード間で記述に差分が無いようにコピーしてお使いください。 (これらは計算ノードでも同様です。全て揃えましょう)
その他、fstabに今回のefsのような共有ディレクトリを自動マウントするよう登録しておくことも実施すべきかと思います。なお計算ノードの設定は参考[1]のままのため説明を省略します。
設定完了後の動作チェック
主系/待機系で設定が完了したら以下を実行して両系統がUpになっているか確認します。
### 主系/待機系の管理ノードで同様に以下が出力されることを確認する。
scontrol ping
Slurmctld(primary) at Slurm-Master is UP
Slurmctld(backup) at Slurm-Secondary is UP
### 特に待機系からも以下のようにジョブの投入/状態確認ができることを確認する。
ubuntu@Slurm-Secondary:/efs$ sbatch sleep.sh
Submitted batch job 12
ubuntu@Slurm-Secondary:/efs$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
Partition01* up infinite 1 mix compute01
ubuntu@Slurm-Secondary:/efs$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
12 Partition test-sle ubuntu R 0:09 1 compute01以上で全ての設定が完了しました。なお、本記事で投入しているジョブは全て、5分間sleepを行うだけのジョブとなっています。それでは次に主系Down時のジョブの挙動を観察します。
ジョブ引継ぎの動作検証
冒頭に記載した通り、動作確認したいのは下記の3点です。1個ずつ見ていきます
- 主系でジョブ投入 → 主系 stop slurmctld → 待機系でジョブ参照
- 主系Down時に待機系でジョブ投入 → 主系 start slurmctld → 主系でジョブ参照
- slurmctld.logを参照してFailover時の正常性を確認する
主系でジョブ投入 → 主系 stop slurmctld → 待機系でジョブ参照
下記に一連の操作を実施したときのメッセージを共有します。
### 主系でジョブ投入 + 投入したジョブの参照
ubuntu@Slurm-Master:/efs$ sbatch sleep.sh
Submitted batch job 14
ubuntu@Slurm-Master:/efs$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
14 Partition test-sle ubuntu R 0:03 1 compute01
### 主系でSlurmctldを止めてみる
ubuntu@Slurm-Master:/efs$ sudo systemctl stop slurmctld
### 応答が返ってこなくなる (待機系へ処理が移譲された後は応答が返ってくる模様)
ubuntu@Slurm-Master:/efs$ squeue上記の実行後すぐに待機系でジョブの稼働様子を参照してみます。
### ジョブを参照しても、2-3分応答がない状況に陥るが、
### 放置しているとジョブが「Running」状態で表示されることを確認できた。
root@Slurm-Secondary:~# squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
14 Partition test-sle ubuntu R 4:26 1 compute01
### 管理ノードの状態を参照すると、確かに待機系のみが生存していることを確認できる。
root@Slurm-Secondary:~# scontrol ping
Slurmctld(primary) at Slurm-Master is DOWN
Slurmctld(backup) at Slurm-Secondary is UP
*****************************************
** RESTORE SLURMCTLD DAEMON TO SERVICE **
*****************************************
### 先に/var/log/slurm/slurmctld.logの末尾を参照すると、JobId=14が正常終了していることが分かる
[2025-12-19T05:32:17.602] _job_complete: JobId=14 WEXITSTATUS 0
[2025-12-19T05:32:17.603] _job_complete: JobId=14 done一連の結果からジョブが正常終了し、管理ノードの冗長化に成功していると理解しました。
主系Down時に待機系でジョブ投入 → 主系 start slurmctld → 主系でジョブ参照
当然、主系がDownした後は復旧作業が発生します。待機系を運用したまま、主系を復旧させることを想定して、slurmctldを再開するときの操作感や表示内容の変化を見てみます。
### 待機系でジョブを投入 + 稼働状況の参照
ubuntu@Slurm-Secondary:/efs$ sbatch sleep.sh
Submitted batch job 17
### 利用者目線では何の問題もなくジョブが稼働している
ubuntu@Slurm-Secondary:/efs$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
17 Partition test-sle ubuntu R 0:09 1 compute01ジョブ投入後、主系に操作を切り替えてslurmctldを再度開始してみます。
### ジョブ投入後すぐに主系のSlurmctldを開始して動作チェック
ubuntu@Slurm-Master:/efs$ sudo systemctl start slurmctld
### サービス起動後、ほぼノータイムでsqueueの応答が返ってくることを確認した
ubuntu@Slurm-Master:/efs$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
17 Partition test-sle ubuntu R 0:54 1 compute01
### 2台ともUPになり、エラーメッセージが表示されないことを確認できる
ubuntu@Slurm-Master:/efs$ scontrol ping
Slurmctld(primary) at Slurm-Master is UP
Slurmctld(backup) at Slurm-Secondary is UP
### 先にSlurmctldの末尾を確認。テスト投入したジョブが正常に終了していることを参照できる。
[2025-12-19T06:13:19.467] _job_complete: JobId=17 WEXITSTATUS 0
[2025-12-19T06:13:19.468] _job_complete: JobId=17 done復旧完了。やはりジョブが正常終了していることを確認できます。主系のサービスを再度上げるときは、あっさり完了する印象を受けました。
slurmctld.logを参照してFailover時の正常性を確認する
一連の流れを経て、主系/待機系のslurmctldに残されているログを見てみます。長いため一部内容を省略しますが、ログが確認されたマシンがどれか分かるようにコメント文を記載します。
### 主系:サービスを停止させた瞬間のログ/ジョブのステータスを保存している様子が見られる
[2025-12-19T05:27:16.715] _slurm_rpc_submit_batch_job: JobId=14 InitPrio=1 usec=29965
[2025-12-19T05:27:17.000] error: _refresh_assoc_mgr_qos_list: no new list given back keeping cached one.
[2025-12-19T05:27:17.000] sched: JobId=14 has invalid account
[2025-12-19T05:27:17.547] sched/backfill: _start_job: Started JobId=14 in Partition01 on compute01
[2025-12-19T05:28:28.420] Terminate signal (SIGINT or SIGTERM) received
[2025-12-19T05:28:28.421] Saving all slurm state
### 待機系:Heartbeatが確認できなくなり、ジョブ等の復旧 → 主系への移行が確認できる
[2025-12-19T05:30:46.166] error: ControlMachine Slurm-Master not responding, BackupController1 Slurm-Secondary taking over
[2025-12-19T05:30:46.166] Terminate signal (SIGINT or SIGTERM) received
[2025-12-19T05:30:46.224] Recovered JobId=14 StepId=batch
[2025-12-19T05:30:46.224] Recovered JobId=14 Assoc=0
[2025-12-19T05:30:46.228] Recovered state of 1 partitions
(中略)
[2025-12-19T05:30:46.236] Running as primary controller
### 主系:復旧時のログの末尾には確かに下記が出力されていることを確認した。
(中略)
[2025-12-19T06:09:08.309] Running as primary controller所感
内容さえ把握すれば、そこまで苦労せずに管理ノードの冗長化が実現できます。もちろんジョブ実行前後にProlog/Epilog設定を含めている場合や、ジョブのAcounting情報を収集する際にはもう少し設定が複雑になるかもしれません。
利用者が要求するサービスレベルに合わせて設定してみる価値はありそうだなと思いました。Slurmの設定って日本語の記事が少ない気がしますね。
参考情報
[1] LLM時代に必須!?トレーニングジョブを管理するSlurmのセットアップ手順
[2] Slurm System Configuration Tool
以上
コメントを残す