目次
はじめに
インフラエンジニアとして仕事をしていると、ユーザから「システムの調子が悪い!」といったフワッとした問い合わせを受けることがあります。
もちろん、問い合わせを受けてサーバへSSH接続しに行ったり、何らかのダッシュボードを参照してみるのもよいですが、場合によっては、外出中ですぐにPCを触れなかったり、十分に調査時間が取れないこともあるかと思います。
また、初動でターミナル操作ばかりに注力してしまうと、間違えた原因に飛びついてしまい、時間だけが経過してしまうなんてこともあるかと思います。 (私はこれで何度も敗北しています)
そんな時でも、広い視点を持ちつつ、迅速に障害要因や被疑箇所を特定するための方法をまとめたいと思い、記事を書きました。
ここで記載する内容は、広くインフラ系の領域に当てはまる内容かと考えています。以降に示す切り分けの質問を行うことで過去の私の感覚では (体感) 70%くらいの割合で被疑箇所を特定できました。
KT法とは?
唐突ですが、皆様はKT法という言葉をご存じでしょうか?
KT法とはKepner-Tregoe法の略称で、問題解決+意思決定の思考プロセスを体系化した考え方の枠組みです。
KT法の思考プロセスは大きく分けて下記の4つの要素から構成されています。
- 状況把握 (Situation Appraisal: SA)
- 問題分析 (Problem Analysis: PA)
- 決定分析 (Decision Analysis: DA)
- 潜在的問題分析 (Potential Problem Analysis: PPA)
上記の中でも、システム不具合時の要因切り分けを行う際は問題分析 (PA) が有効です。
問題分析 (PA) は問題を明確化し、本来あるべき姿と現状で差異が生じている原因を究明するための思考プロセスです。
以降では、問題分析 (PA) にのみフォーカスを当てて話を進めますが、他の3つの思考プロセスも非常に役に立つため、お時間のある方はぜひ調べてみてください。
問題分析 (PA) の流れと観点について
まず先に、障害発生時における問題分析 (PA) の流れを示すと、下図のようになります。
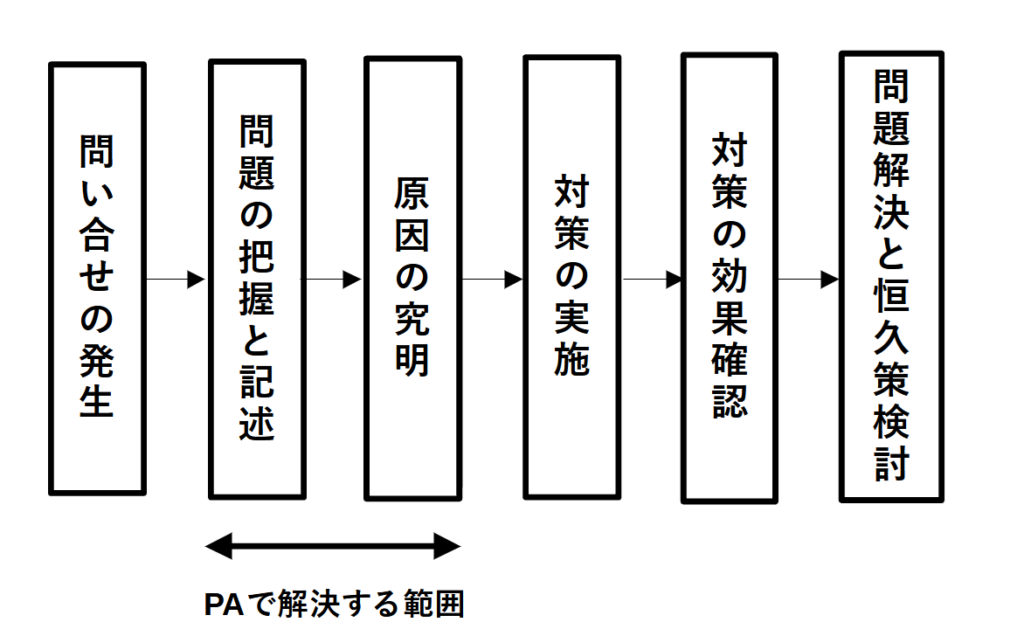
上図の「原因の究明」を実現する際に重要であるのが問題を網羅的にヒアリングし把握すること、すなわち「問題の把握と記述」をヌケ・モレ無く遂行することにかかっています。
「問題の把握/記述」を網羅的に実施する上で、PAでは下記の2つの観点に基づいてヒアリングや調査を行います。
- 3W + 1E
- IS / IS NOT
それぞれの観点を更に分解し、質問すべき内容を簡単に説明します。
- 3W + 1E
- What:どんな問題が起こっているのか、何が問題なのか
- Where:問題が生じている場所や対象
- When:問題が生じた(or 最初に確認した)日時、発生パターンやタイミング
- Extent:問題に関する定量的なデータ (ディスク容量やファイル数、応答速度など)
- IS / IS NOT
- IS:問題や事象が発生するケース
- IS NOT:問題や事象が発生しないケース
では、実際に上記の観点 (3W+1EとIS / IS NOT) に基づいた質問リストの例を記載します。
質問リスト
- システムに不具合があると判断されたのはなぜですか?(What)
- その不具合がどのようになれば、問題が解消したと判断できますか?(What)
- その不具合は他の人(or 他のサーバやアプリケーション)でも確認されていますか?
あるいは、あなたにのみ発生している事象ですか? (Where, IS, IS NOT) - 直近でハード面/ソフト面でシステムに変更を加えた部分はありますか?(Where)
- いつからシステムに不調が発生していますか?(When)
- 最後にシステムが正常に動作していることを確認されたのはいつですか?(When)
- パフォーマンス上の問題等であればそれは定量的なデータとして表現は可能ですか?(Extent)
- 事象の発生頻度や発生パターンなどはありますか?(Extent)
上記の質問リストから得られた回答を基に想定される原因について仮説を立て、仮説を裏付けるように原因を調査していく (例:ログを参照するなど) ことで、原因究明を行います。
問題を悪化させないことが分かっている状況であれば、要因を裏付けるための再現性確認テストなどを実施してもよいかと思います。
ヒアリング等から判明した事項は、こちら (参考[1]) の記事のように、マトリックス形式でまとめると分かりやすいかと思います。以下に参考[1]から、まとめ方の例を引用します。
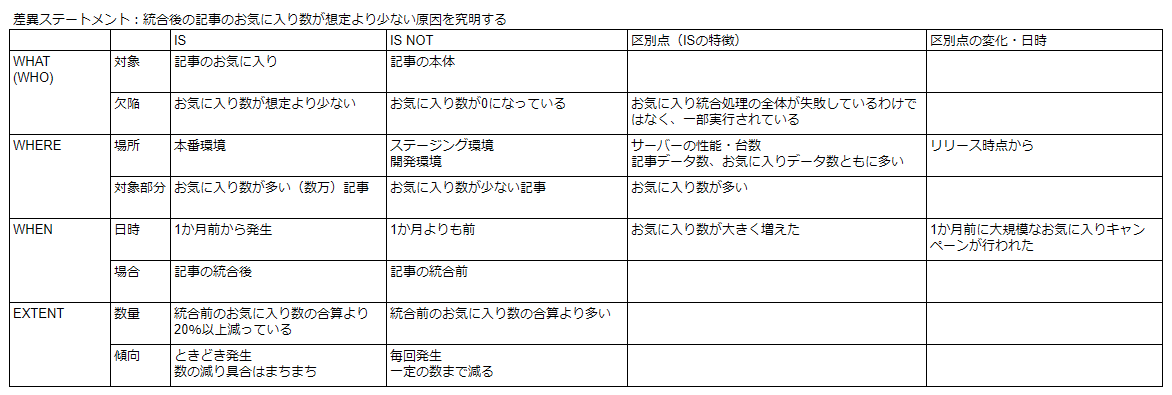
細かいまとめ方などは各自、分かりやすいように実施いただければと思いますが、ここまでの調査だけで究明できる問題については、せいぜい紙とペンさえあれば十分だと思います。
また、既にお気づきの方がいらっしゃるかもしれませんが、実はこれらの質問リストは「詳解システム・パフォーマンス」(参考[2]) のコアとなる第2章にも記載されている質問が多数含まれています(一部の質問内容を私が追記)。
(余談ですが、KT法の考え方と詳解システム・パフォーマンスの着眼点に類似点を感じたことから本記事を書きたいと思った部分も大きいのです・・・)
問題箇所切り分けのための簡易調査コマンド
ここからは実際にコマンドを入力しての操作となります。
ターミナルを触れる状況であれば、上記ヒアリングと並行で実施できるとよいかと思います。
特にLinux系OSでのパフォーマンス障害発生時において60秒で完了する簡易的な調査コマンドとして先述の「詳解システム・パフォーマンス」に取り上げられており、私自身も重宝することがあったため、メモ 兼 備忘録的に記載させていただきます。
(※ なお、下記コマンド群を実行する場合はsysstatパッケージが必要です。)
##### 60秒で実行できるLinuxパフォーマンス調査コマンド
### 1分, 5分, 15分ごとの負荷状況を確認する。
> uptime
### OOM (Out of Memory)発生時の確認など。Docker利用時に発生しがち。
> dmesg -T | tail
### Memory/Swap/IO/CPUの利用状況など広範囲な状況を1秒ごとに取得する。
> vmstat -SM 1
### 全CPUの使用状況を1秒間隔で出力。HPC系の並列処理の動作状況確認にも使える。
> mpstat -P ALL 1
### 各プロセスのCPU利用状況を1秒間隔で出力する。
> pidstat 1
### 各ディスクのI/Oに関する状況を1秒間隔で出力する。(実行中に変化のないものは出力せず)
> iostat -sxz 1
### Swapを含めたMemoryの利用状況を参照する。
> free -m
### 全NICにおけるパケットの送受信状況やスループットを出力する。
> sar -n DEV 1
### TCP通信における統計情報を表示する。(個人的にあまり使っていない気がする)
> sar -n TCP,ETCP 1
### システム全体の動作チェックする。htopよりも軽量に動作するのでtopを使用する。
> topおわりに
ということでKT法に則ったシステム障害発生時の簡単な初動対応について記載しました。
問題が発生した時、闇雲に知っているコマンドを実行するだけであったり、適当に設定値を変更したり…といったアンチメソッドを昔の私はよくやっていました。
しかし、障害発生時には迅速かつ広い視点を持った調査方法が必要になります。記事としてまとめておくことで私自身も、本投稿を見返し、心にゆとりをもって調査が行えますし、また、これがどなたかのお役に立てられれば幸いです。
もし、「こんな観点もあるよ!」とか「こんな項目も盛り込めるといいよね!」といったものがあればお気軽にコメントをいただければと思います。
以上
コメントを残す